Introduction
In this post I will show how you can use two different caching approaches in the .NET environment. The former approach is the in-memory cache whereas the latter one is the distributed cache. Apart form the implementation itself I will show performance benefits of them as well.
At the beginning let me introduce a cache-type-agnostic guideline that you should consider during your cache implementation:
- Application can not depend on the values available in cache. There must be a fallback in case of missing cache data.
- Cached objects should not be defined by a user (unpredictable size).
- Cache entries should have time to live (expiration time) set.
- Cached objects should have size limit.
In-memory cache
In-memory cache as the name suggests is a type of cache that stores the data in a local memory. There is great and concise explanation of the in-memory cache.
Cached objects are stored in the memory thus the time of reading is incredibly fast (probably the fastest cache approach). For this reason one has to be aware of the following consequences:
- Sessions should be sticky (what is a sticky session) to avoid cache consistency problems,
- In-memory cache uses the same memory as the main app.
.NET provides IMemoryCache interface so the implementation is rather straightforward.
Distributed cache
Distributed cache is typically an external service that is accessible to other servers. It is important to mention that distributed cache (as an external resource) does not waste local memory of the main app. Similarly to the in-memory cache there is a succinct explanation of the distributed cache on the Microsoft docs website. Fortunately, distributed cache implementation is pretty easy in the .NET environment as it can be done via unified IDistributedCache interface.
Benchmark
Enough theory, let’s move to the real code. I prepared a simple application to demonstrate benefits of the multi-layer cache usage. The big picture of it looks like this:
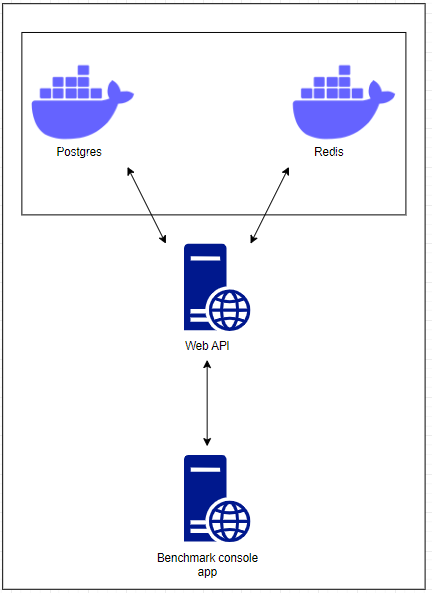
There are three components regarding the main application implementation:
- Postgres (running as a docker container),
- Redis (running as a docker container),
- Web API (running as a .NET Web API app – not in a docker container).
The main application can store data in a three different layers:
- In-memory cache,
- Distributed cache,
- Main storage – database.
There is also fourth component which is Benchmark console app. The console app was created to perform benchmark tests that consist of sending GET HTTP requests to the Web API application to read the stored data and compare times when data is read from the in-memory cache, distributed cache (Redis) and from the main storage (Postgres). Benchmark results for 50 HTTP Get requests (sent from the console app to the Web API) are as follows:

There are three tests:
- GetFromInMemory – sends GET HTTP requests to the Web API. The Web API reads the data from the in-memory cache and returns in a HTTP response.
- GetFromRedisCache – sends GET HTTP requests to the Web API. The Web API reads the data from the distributed cache (Redis) and returns in a HTTP response.
- GetFromPostgres – sends the GET HTTP requests to the Web API. The Web API reads the data from the main storage (Postgres) and returns in a HTTP response.
The benchmark results clearly show that the read operation from a cache can safe a lot of time. Reading data from the main storage is the slowest possible option ever. However, as mentioned before the cache is not a perfect solution as it has limited size and can not be treated as a source of truth.
Summary
To sum up, caching is a crucial part of the web application. Thanks to the proper caching strategy read operation time can be decreased hence increasing the user experience and the overall application performance.
It is worth to mention that the presented benchmark does not copy the real world scenario. The Postgres database has precious little records in the benchmark scenarios. Real world databases have much more of them thus the read operation from the main storage would be even longer.
As always I prepared an example and you can find it on my GitHub, Web API project: cache, console app project: caching, benchmark project: cache-benchmark. If you would like to run the application locally you should run the following commands in the cache project directory:
docker-compose build; docker-compose up -d; dotnet run -c Release;
Once that done you can open the browser and paste swagger URL: http://localhost:5000/swagger/index.html
Have a nice day, bye!
Be First to Comment