Introduction
In this post I won’t be describing stuff strictly related to the .NET. The data locality topic is more about the processor cache and how it can affect the execution time of your application. Don’t worry though, the proper benchmark and the code itself will be written in C#, so read on! In the previous post I had unit tests but no benchmark. This time both the benchmark and unit tests are with us!
Quick test
Before we deep dive into the data locality I have a question for you. Let’s consider the following code snippets:
public void IterateWriteSequential()
{
for (int i = 0; i < _size; i++)
{
for (int j = 0; j < _size; j++)
{
_array[i, j] = 5;
}
}
}public void IterateWriteNonSequential()
{
for (int i = 0; i < _size; i++)
{
for (int j = 0; j < _size; j++)
{
_array[j, i] = 5;
}
}
}The code snippets are pretty straightforward (no tricky stuff here). Both of them do the same – assignment of “5” to all fields of the multidimensional array. The only difference is that the IterateWriteSequential method does it in row-by-row and the IterateWriteNonSequential method does it in a column-by-column way. In the test project you can ensure that the methods do the same.
So, how the way the iteration goes through the multidimensional array can affect the execution time of your application?
There are three options you can choose from:
- You have no idea.
- You exactly know what’s going on.
- You are not sure, but you guess.
No matter what your answer is you should read on either to find out or verify my explanation of the topic.
Benchamrk – execution time
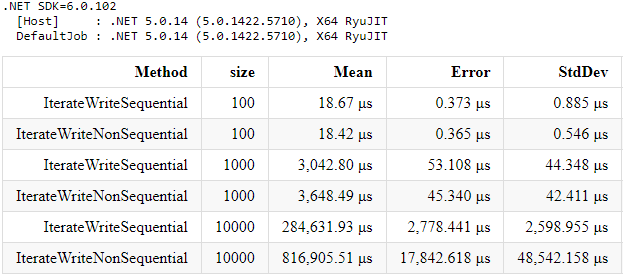
Let’s take a look at the benchmark results of the aforementioned methods (size means the rows/columns count, size = 100 means an array 100×100):
I also ran similar benchmark but for the case with jagged array (i.e. int[][] instead of int[,]). Here are the benchmark results:
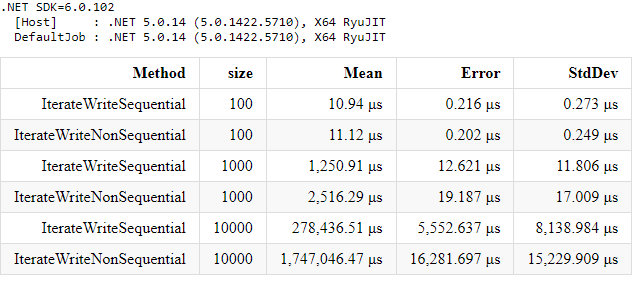
As you can see for the small arrays (size = 100) it does not matter, but as the array size increases, increases the execution time difference (significantly). Let’s focus on the greatest size, i.e. 10_000 (100_000_000 elements). For multidimensional array the IterateWriteSequential method execution time is almost 3 times faster than the IterateWriteNonSequential. For the jagged array the difference is even bigger. The IterateWriteSequential method is more than 6 times faster! Pretty impressive, isn’t it?
Explanation
First of all let’s take a look at how the DRAM memory is organised. The DRAM cells are packed into matrices. To read the cell the row and the column in required. Sequential read (row number the same, iterate through columns) is much faster than reading the data by frequently changing row (not in a sequential manner).
Secondly, there is the processor cache. When the processor needs to read form the memory it firstly tries to take it from its cache. If it is not present in the cache it fetches the data from the DRAM memory. It is obvious that the cache data fetching is much faster that the fetching from the RAM. To transfer data from DRAM to the cache a cache line is used. The cache line is fixed size (most commonly 64 bytes). It means you cannot transfer only 1 byte to your cache, all 64 bytes will be fetched. With this in mind we can imagine how bad “DRAM->cache” data transfer looks like when it comes to iterate through array in a non-sequential way. Reading consecutive elements (in non-sequential way) we ask for data that is not next to each other thereby we frequently use “DRAM->cache” transfer. Thanks to this your application, even if semantics is the same, the underlying operations might be way far from optimal.
Summary
Data locality is something that you probably not think of when it comes to write an application. The consequences might never come into play as the data locality don’t matter for small data. However, once in a while the hot-paths of your application might need be improved and the data locality might turn out to be the key to success.
As always I’ve prepared an example and you can find it on my github, project: data-locality, test project: data-locality-tests, benchmark project: data-locality-benchmark. I encourage you to go through the code, debug it and try to test your own scenarios.
Have a nice day, bye!
Great job Tomasz! Very informative.
Thanks!